6 Stey-by-step st-seq pipeline
- Load the R packages.
# sc libraries
library(Seurat)
library(phateR)
library(DoubletFinder)
library(monocle)
library(slingshot)
library(GSVA)
library(limma)
library(plyr)
library(dplyr)
library(org.Mm.eg.db)
library(org.Hs.eg.db)
library(CellChat)
library(velocyto.R)
library(SeuratWrappers)
library(stringr)
library(scran)
library(ggpubr)
library(viridis)
library(pheatmap)
library(parallel)
library(reticulate)
library(SCENIC)
library(feather)
library(AUCell)
library(RcisTarget)
library(Matrix)
library(foreach)
library(doParallel)
library(clusterProfiler)
library(GPTCelltype)
library(openai)
library(HematoMap)
# st libraries
library(RColorBrewer)
library(Rfast2)
library(SeuratDisk)
library(abcCellmap)
library(biomaRt)
library(copykat)
library(gelnet)
library(ggplot2)
library(parallelDist)
library(patchwork)
library(markdown)
# getpot
library(getopt)
library(tools)
# HemaScopeR
library(HemaScopeR)6.1 Step 1. Data loading
The st_Loading_Data function is designed for loading 10X Visium spatial transcriptomics data from Space Ranger. It will load data from input.data.dir and output it in the SeuratObject format.
6.1.1 Function arguments:
input.data.dir: The directory where the input data is stored.output.dir: The directory where the processed output will be saved. If not specified, the output is saved in the current working directory. Default is ‘.’.sampleName: A string naming the sample. Default is ‘Hema_ST’.rds.file: A boolean indicating if the input data is in RDS file format rather than a typical results of Space Ranger. Default is FALSE.filename: The name of the file to be loaded if the data is not in RDS format. Default is “filtered_feature_bc_matrix.h5”.assay: The specific assay to apply to the data. Default is ‘Spatial’.slice: The image slice identifier for the spatial data. Default is ‘slice1’.filter.matrix: A boolean indicating whether to load filtered matrix. Default is TRUE.to.upper: A boolean indicating whether to convert feature names to upper form. Default is FALSE.
6.1.2 Funciton behavior:
- Directory Creation: The function first checks if the
output.direxists; if not, it creates it. - RDS File Handling:
If
rds.fileis TRUE, it reads the RDS file, ensuring the specifiedassayandsliceare present in the Seurat object. - Non-RDS File Handling:
If
rds.fileis FALSE, it loads the data usingLoad10X_SpatialfromSeurat. - Saving the Object:
Uses
SaveH5SeuratandConvertto save the Seurat object in rds and h5ad formats. - File Copying:
Copies any necessary files (filter matrix, spatial image) to the
output.dir. - Return Value: Returns the processed Seurat object.
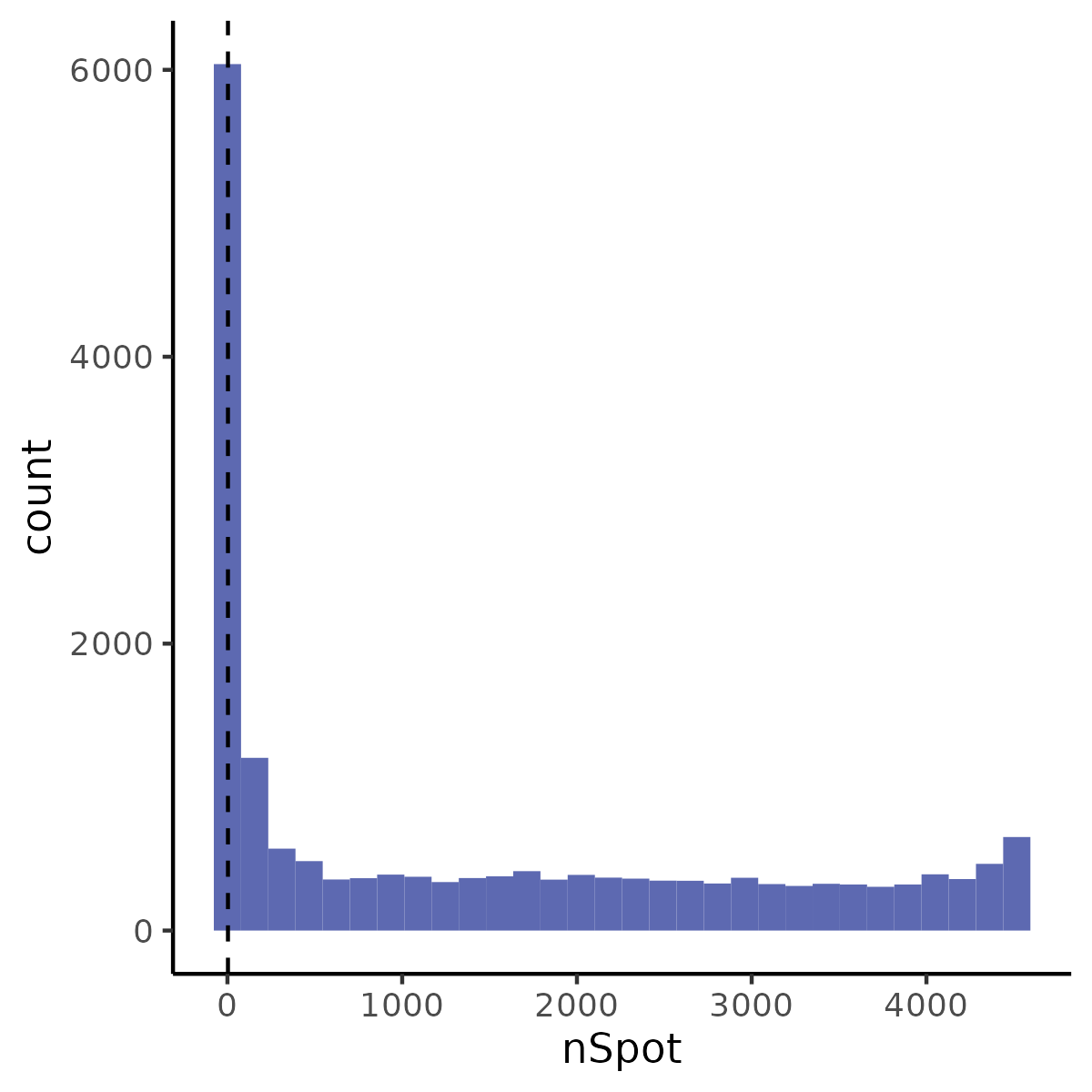
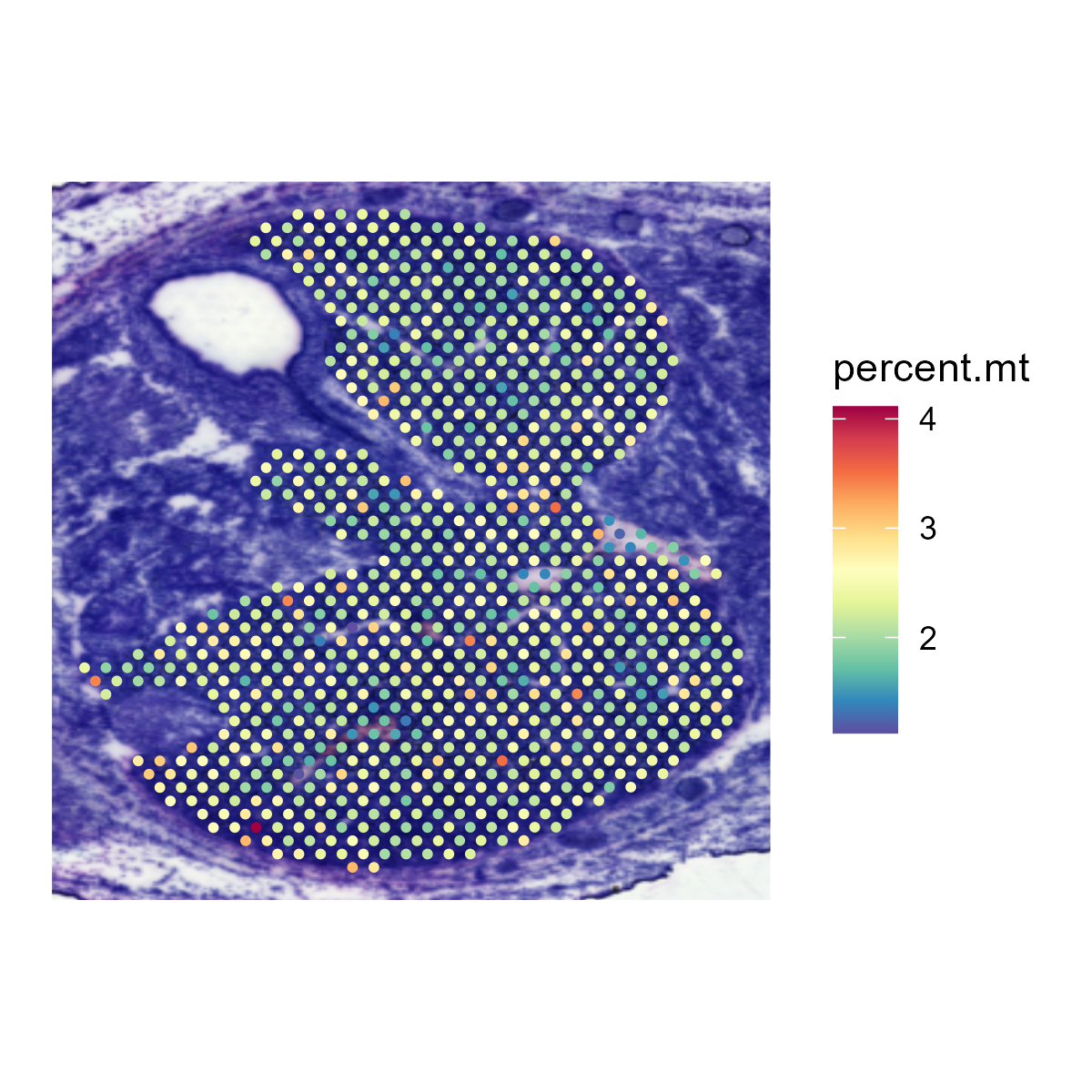
6.2 Step 2. Quality Control
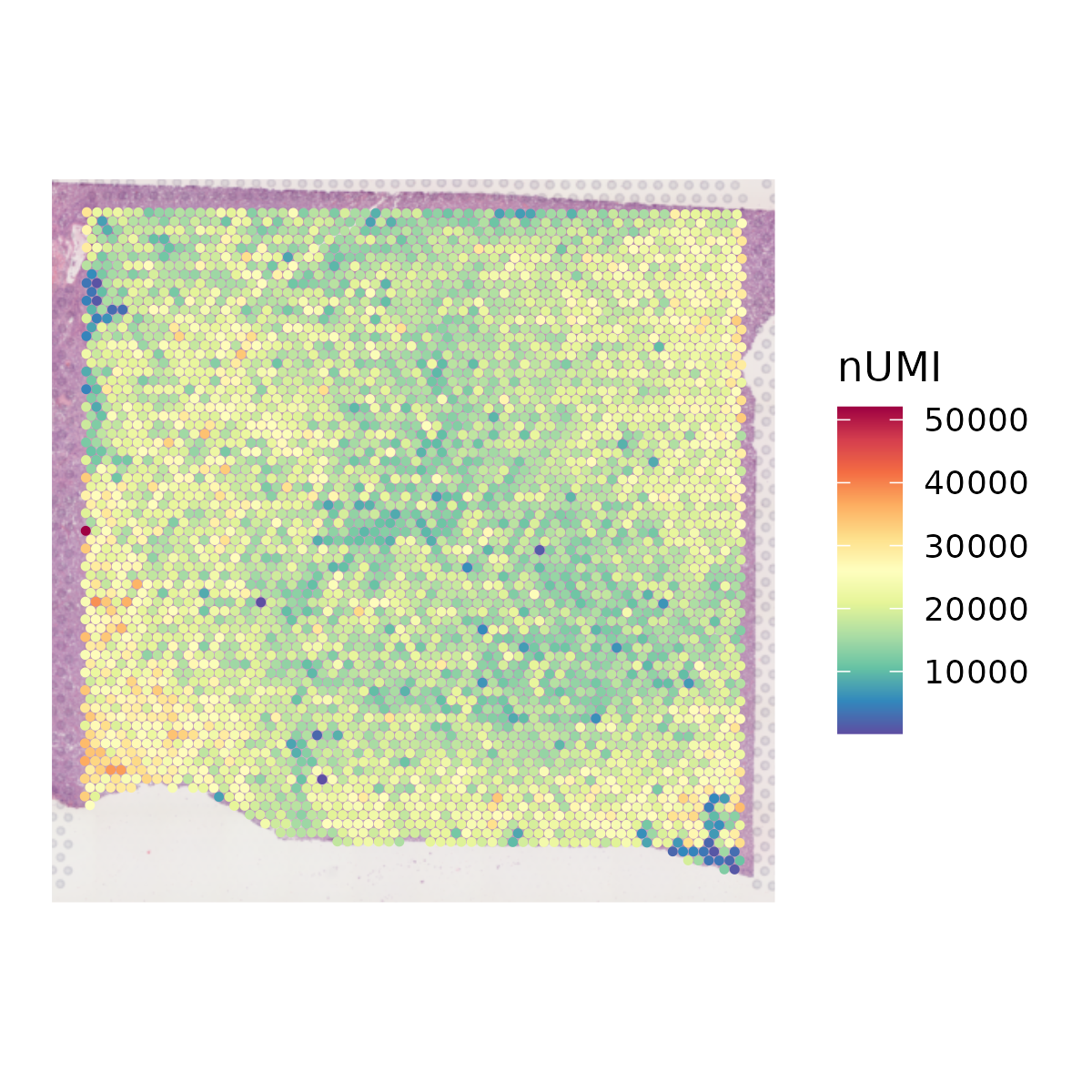
The QC_Spatial function performs basic quality control on a SeuratObject containing 10X visium data and returns the filtered SeuratObject. It provides options to set thresholds for the number of genes, nUMI (unique molecular identifiers), and spots expressing each gene. It also allows for the removal of mitochondrial genes based on species.
6.2.1 Function arguments:
st_obj: A SeuratObject of 10X visium data.output.dir: A character string specifying the path to store the results and figures. Default is the current working directory.min.gene: An integer representing the minimum number of genes detected in a spot. Default is 200.max.gene: An integer representing the maximum number of genes detected in a spot. Default is Inf (no upper limit).min.nUMI: An integer representing the minimum number of nUMI detected in a spot. Default is 500.max.nUMI: An integer representing the maximum number of nUMI detected in a spot. Default is Inf (no upper limit).min.spot: An integer representing the minimum number of spots expressing each gene. Default is 3.species: A character string representing the species of sample, either ‘human’ or ‘mouse’.bool.remove.mito: A boolean value indicating whether to remove mitochondrial genes. Default is TRUE.SpatialColors: A function that interpolates a set of given colors to create new color palettes and color ramps. Default is a color palette with reversed Spectral colors fromRColorBrewer.
6.2.2 Function behavior:
- Plots and saves the spatial distribution of nUMI and nGene.
- Plots and saves violin plots for nUMI and nGene.
- Identifies and marks low-quality spots based on nUMI and nGene thresholds.
- Plots the spatial distribution of quality.
- Plots and saves a histogram for the number of spots expressing each gene.
- Plots the spatial distribution of mitochondrial genes.
- Saves the raw SeuratObject before filtering.
- Removes low-quality spots and genes with fewer occurrences.
- Optionally removes mitochondrial genes.
- Saves the filtered SeuratObject.
- Returns the filtered
st_obj.
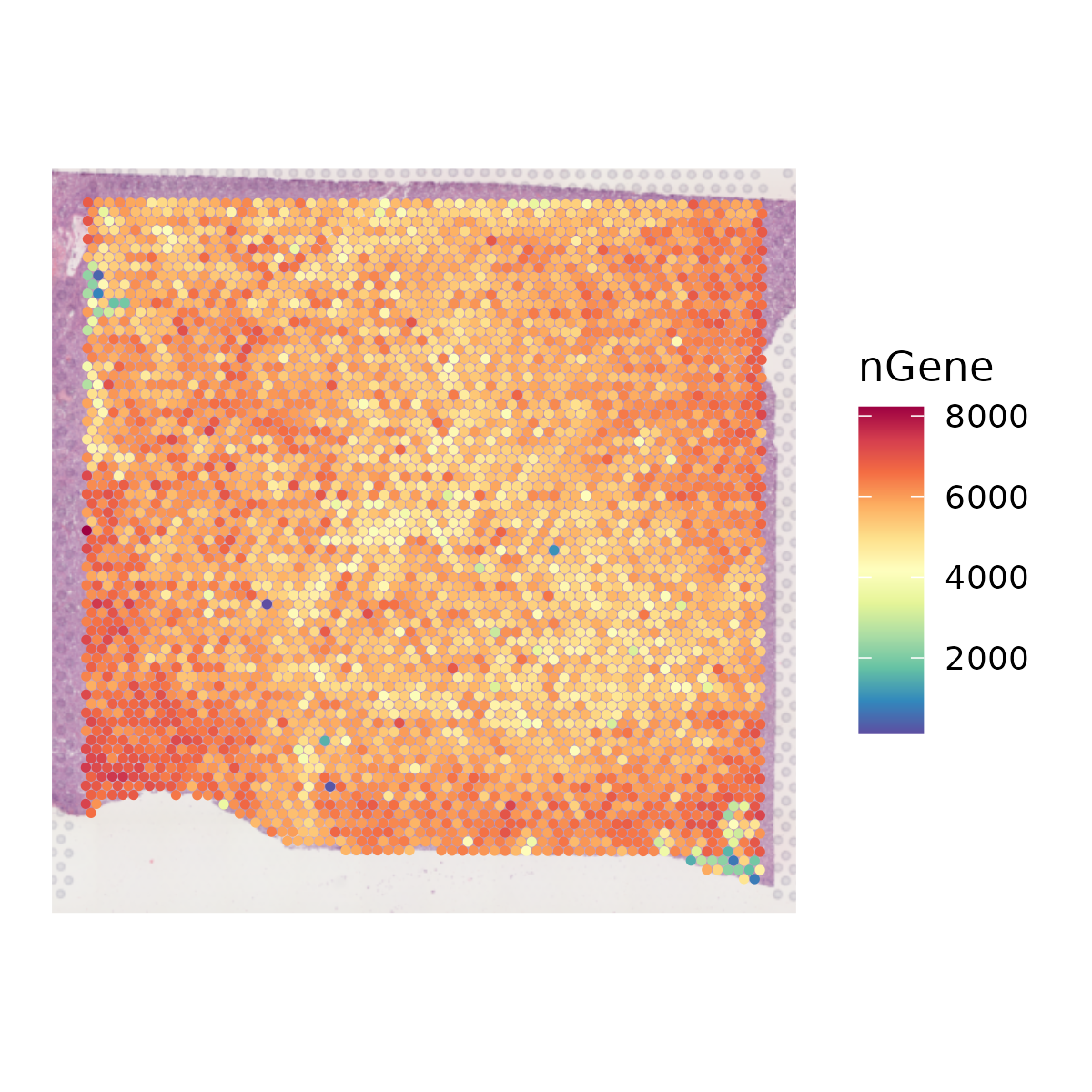
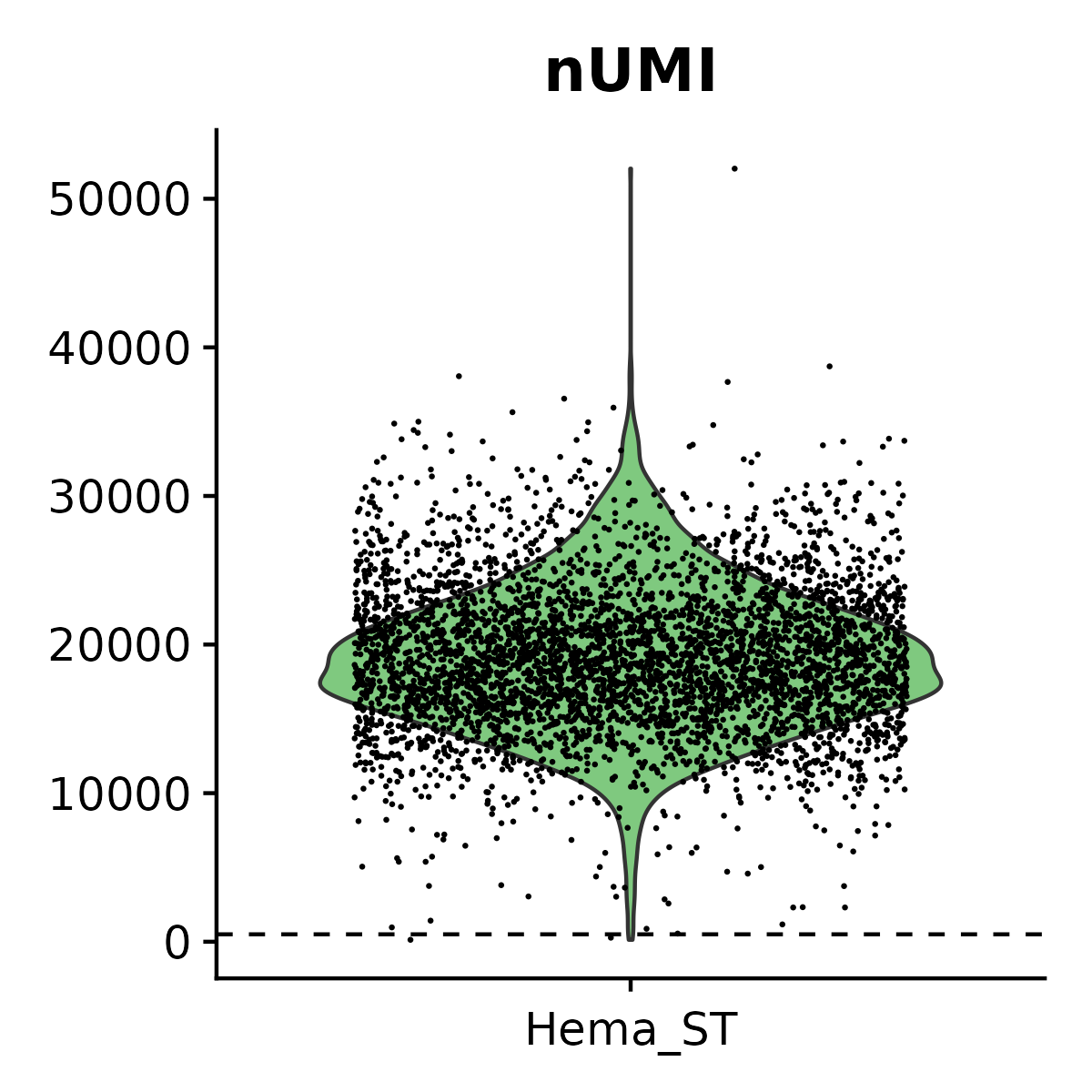
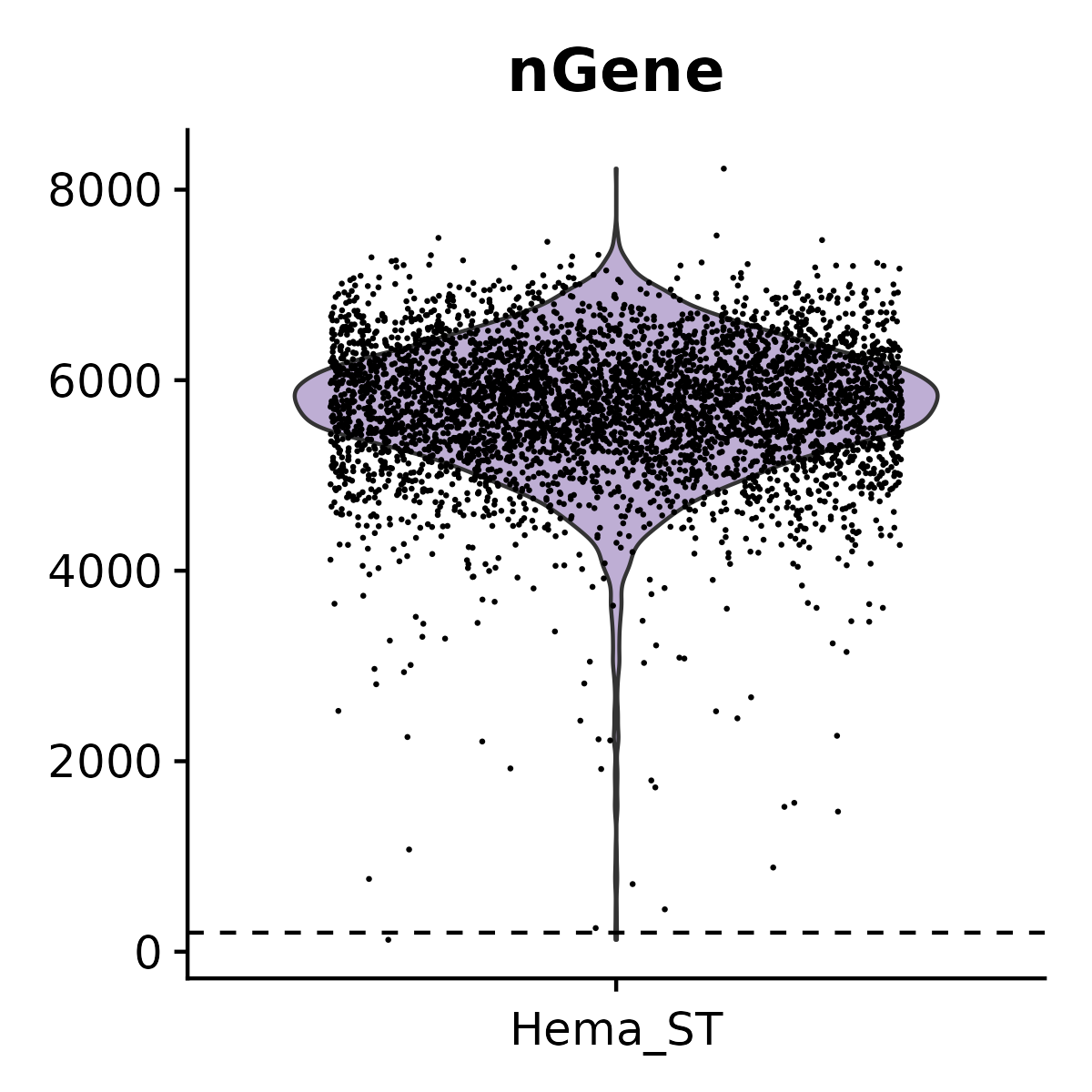
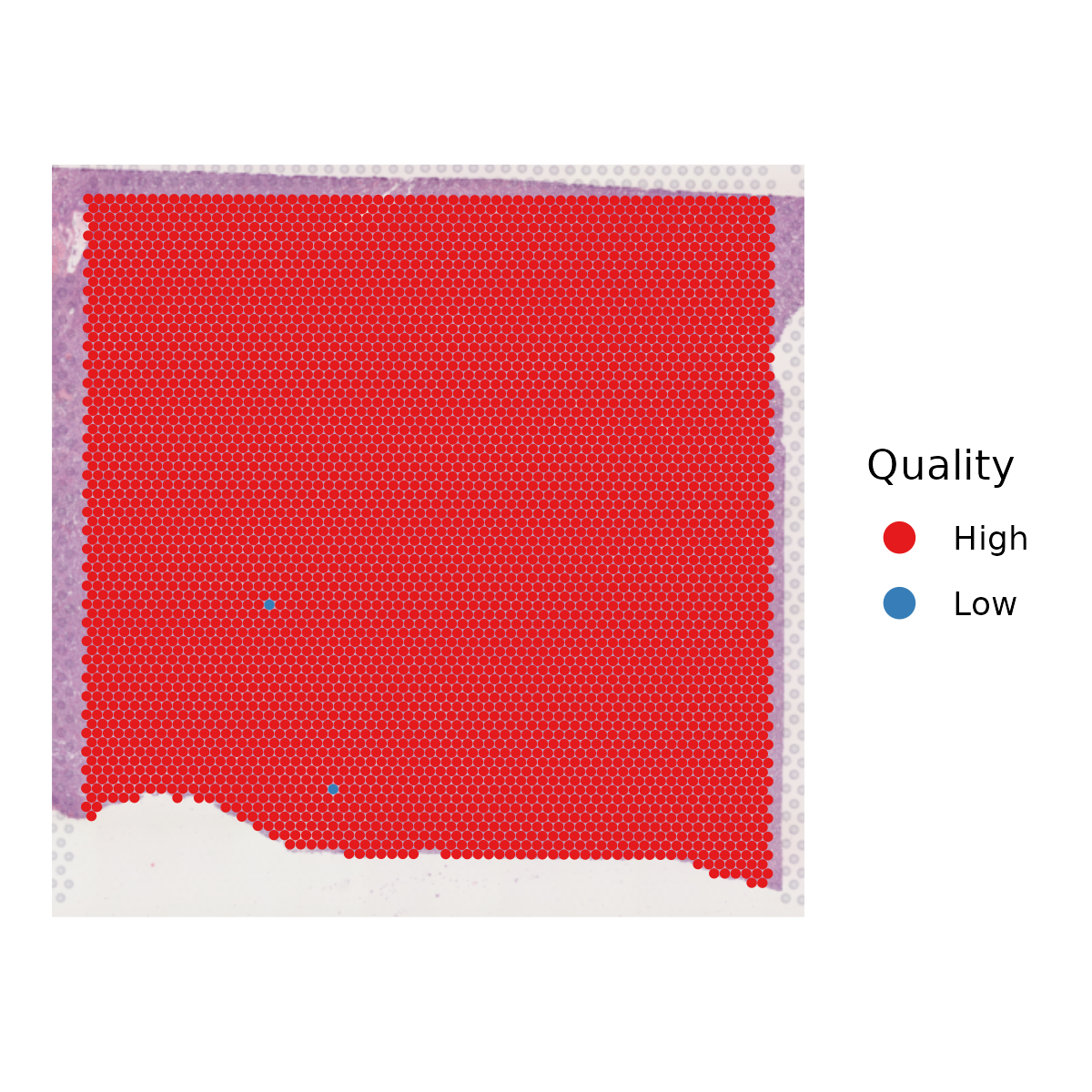
6.3 Step 3. Clustering
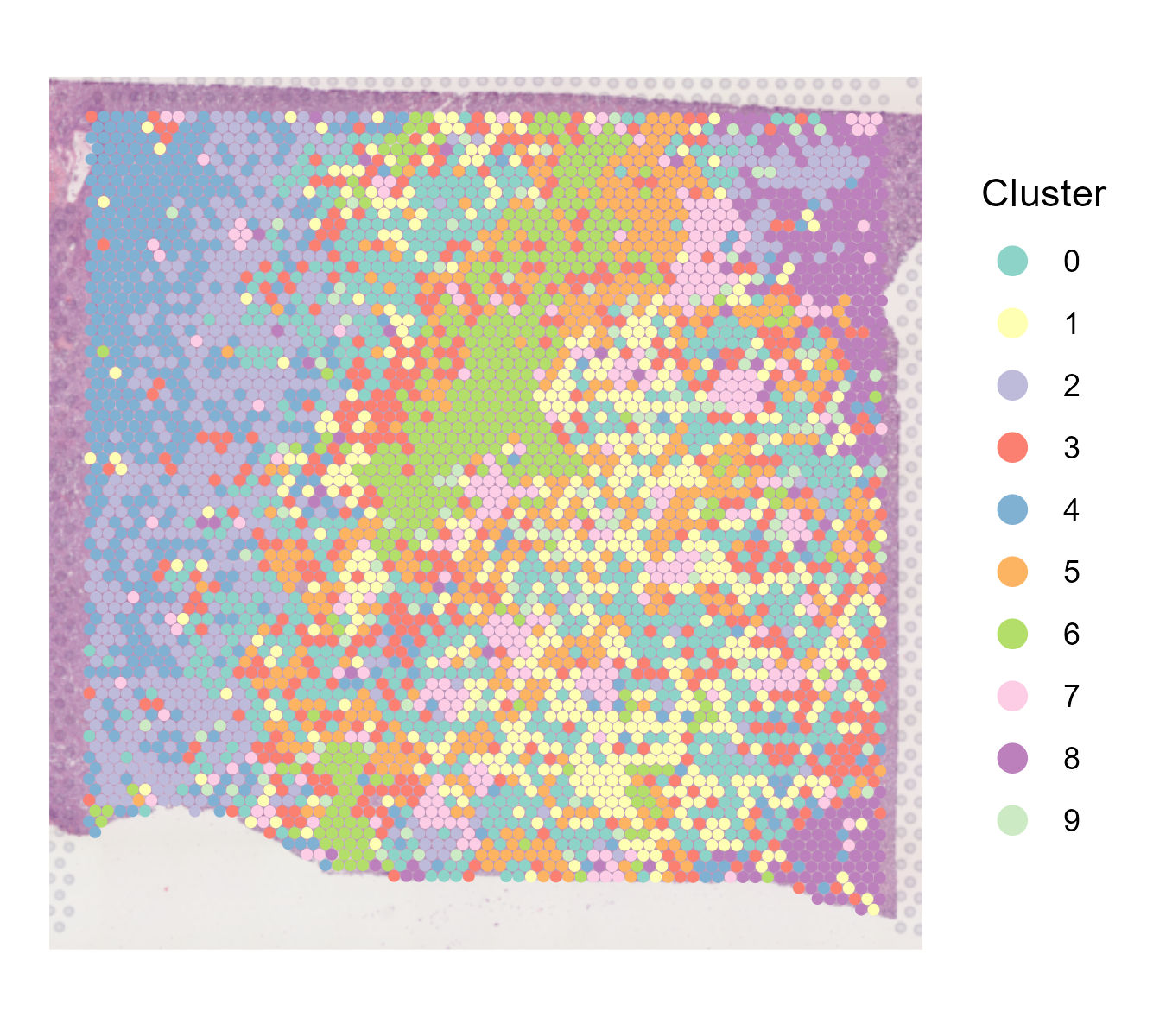
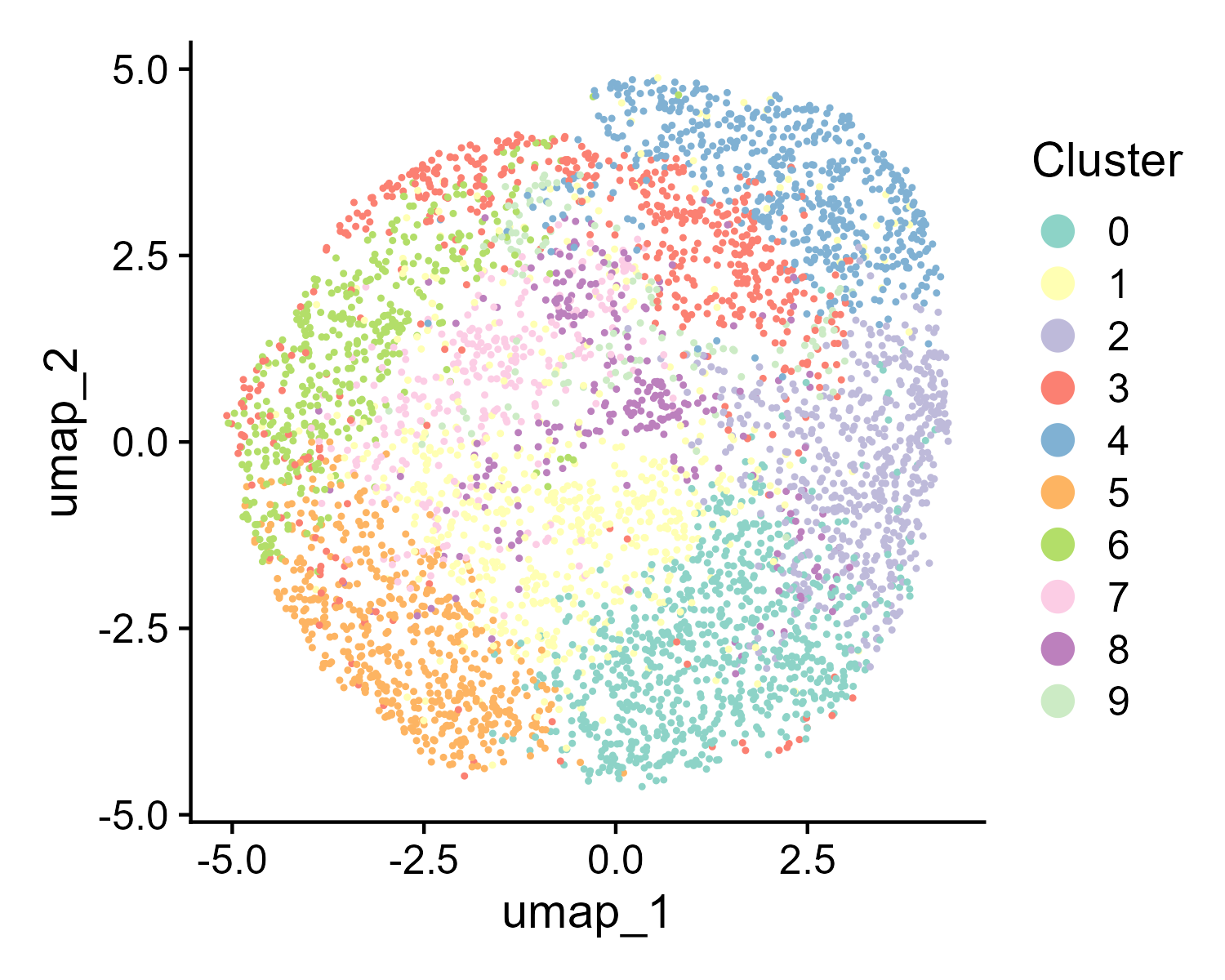
The st_Clustering function is designed to perform clustering analysis on spatial transcriptomics data. It integrates several key steps including data normalization, dimensionality reduction, clustering, and visualization. The function saves the results and visualizations to output.dir.
6.3.1 Function arguments:
st_obj: The input spatial transcriptomics seurat object that contains the data to be clustered.output.dir: The directory where the output files will be saved. Default is the current directory (‘.’).normalization.method: The method used for data normalization. Default is ‘SCTransform’.npcs: The number of principal components to use in PCA. Default is 50.pcs.used: The principal components to use for clustering. Default is the first 10 PCs (1:10).resolution: The resolution parameter for the clustering algorithm. Default is 0.8.verbose: A logical flag to print progress messages. Default is FALSE.
6.3.2 Function behavior:
- Data Normalization and PCA: Depending on the
normalization.method, the function either usesSCTransformor a standard normalization method followed by scaling and variable feature detection. Performs PCA on the normalized data. - Clustering and Dimensionality Reduction: Finds nearest neighbors using the specified principal components (
pcs.used). Identifies clusters using the specifiedresolution. Performs UMAP and t-SNE for visualization of the clusters. - Visualization: Generates spatial, UMAP, and t-SNE plots of the clusters with customized color schemes. Saves these plots as images in the specified directory.
- Saving Results: Saves the updated
st_objas an RDS file. Exports the metadata ofst_objto a CSV file. - Return Value: Returns the updated
st_objcontaining the clustering results.
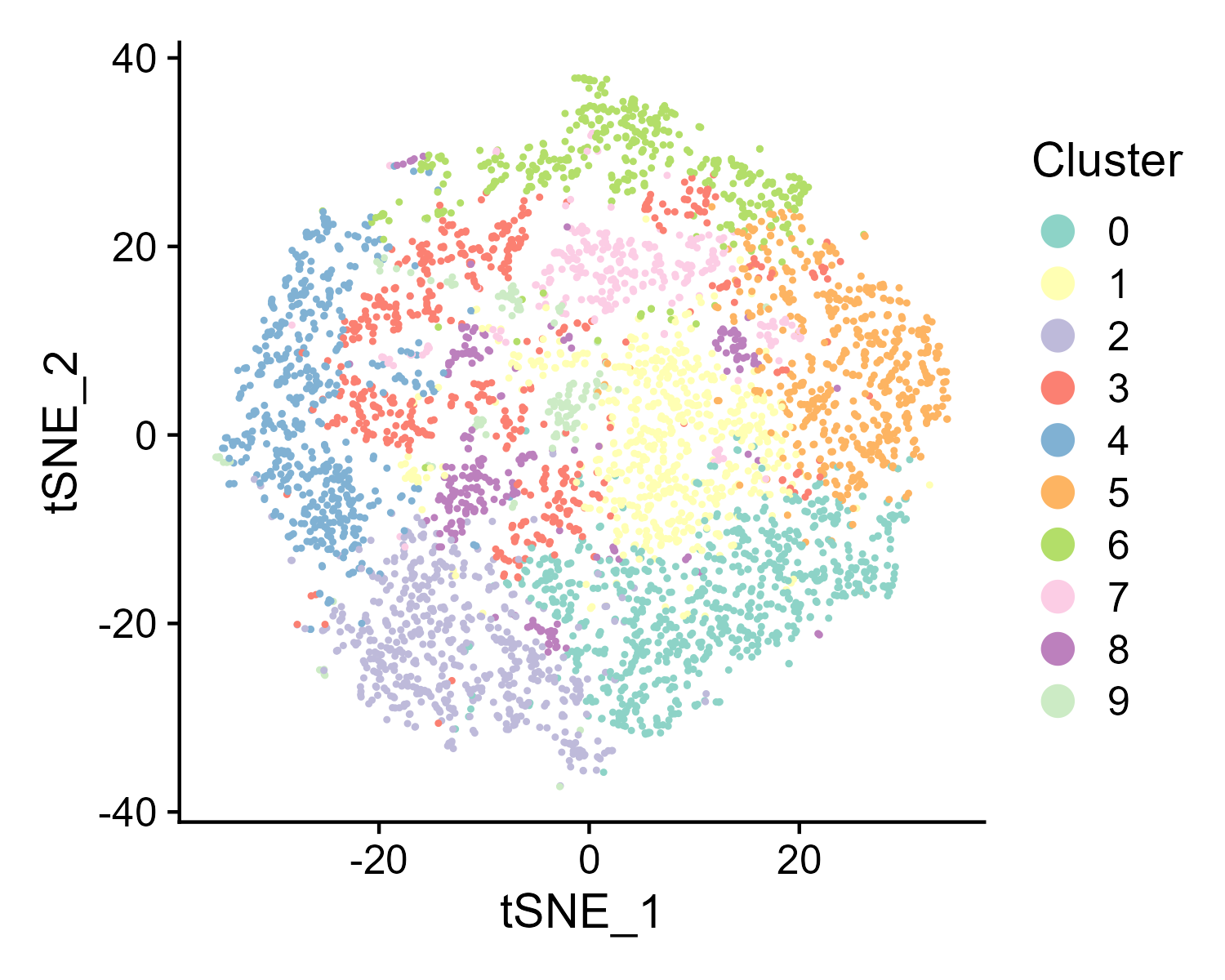
6.4 Step 4. DEGs
The st_Find_DEGs function is designed to identify differentially expressed genes (DEGs) in spatial transcriptomics data. It performs differential expression analysis based on clustering results, visualizes the top markers, and saves the results to output.dir.
6.4.1 Function arguments:
st_obj: The input spatial transcriptomics object containing the data for DEG analysis.output.dir: The directory where output files will be saved. Default is the current directory (‘.’).ident.label: The metadata label used for identifying clusters. Default is'seurat_clusters'.only.pos: A logical flag to include only positive markers. Default is TRUE.min.pct: The minimum fraction of cells expressing the gene in either cluster. Default is0.25.logfc.threshold:The log fold change threshold for considering a gene differentially expressed. Default is0.25.test.use: The statistical test to use for differential expression analysis. Default is'wilcox'.verbose: A logical flag to print progress messages. Default is FALSE.
6.4.2 Function behavior:
- Set Identifiers: Sets the cluster identifiers in the spatial transcriptomics object (
st_obj) based on the specifiedident.label. - Find Differentially Expressed Genes (DEGs): Performs differential expression analysis using the specified parameters (
only.pos,min.pct,logfc.threshold,test.use). - Top Marker Genes: Selects the top 5 marker genes for each cluster based on the highest average log fold change.
- Visualization: Generates a dot plot for the top DEGs and saves the plot as an image in the specified directory.
- Saving Results: Saves the DEG results as a CSV file.
- Return Value: Returns the data frame containing the identified DEGs.
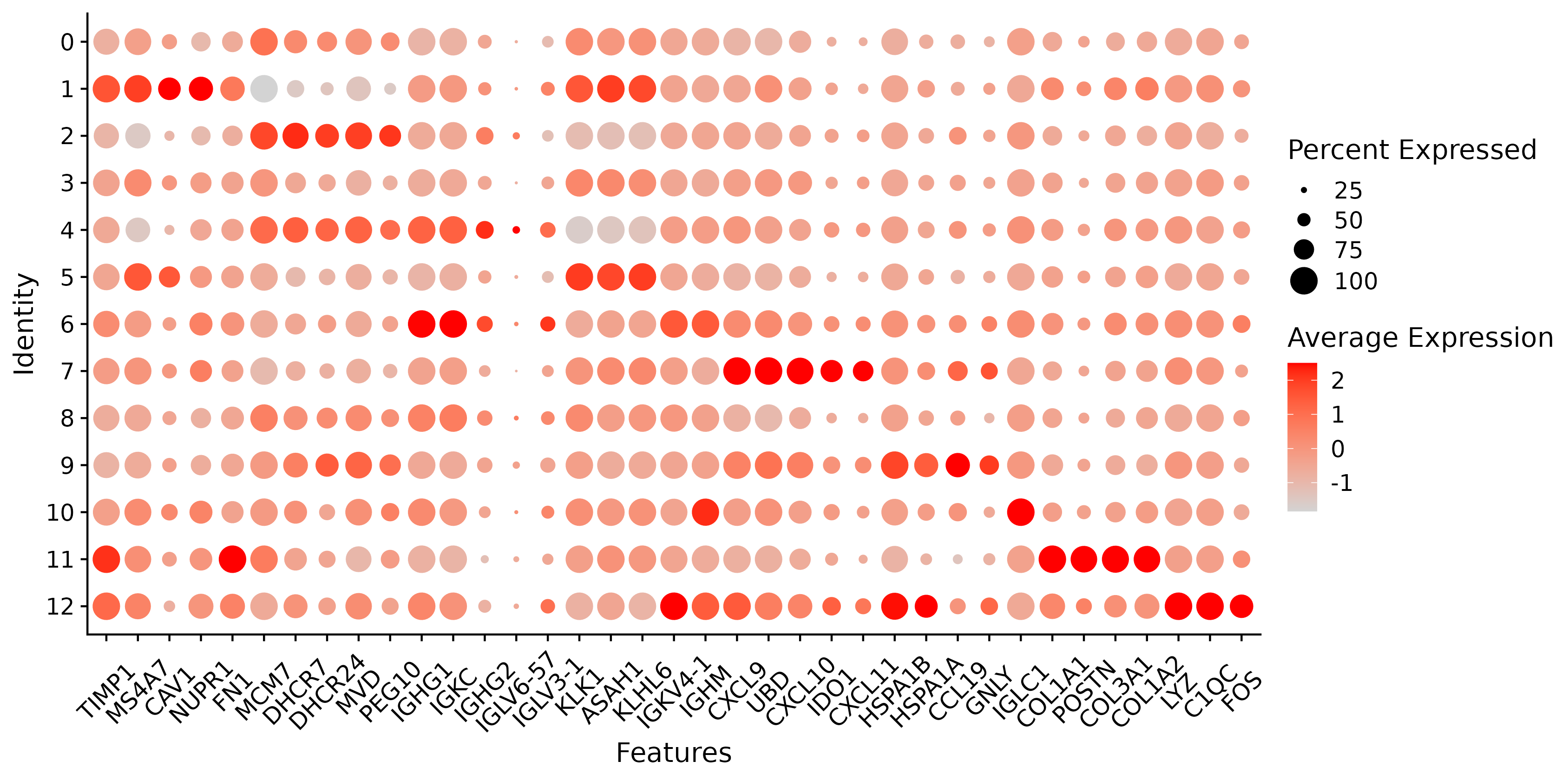
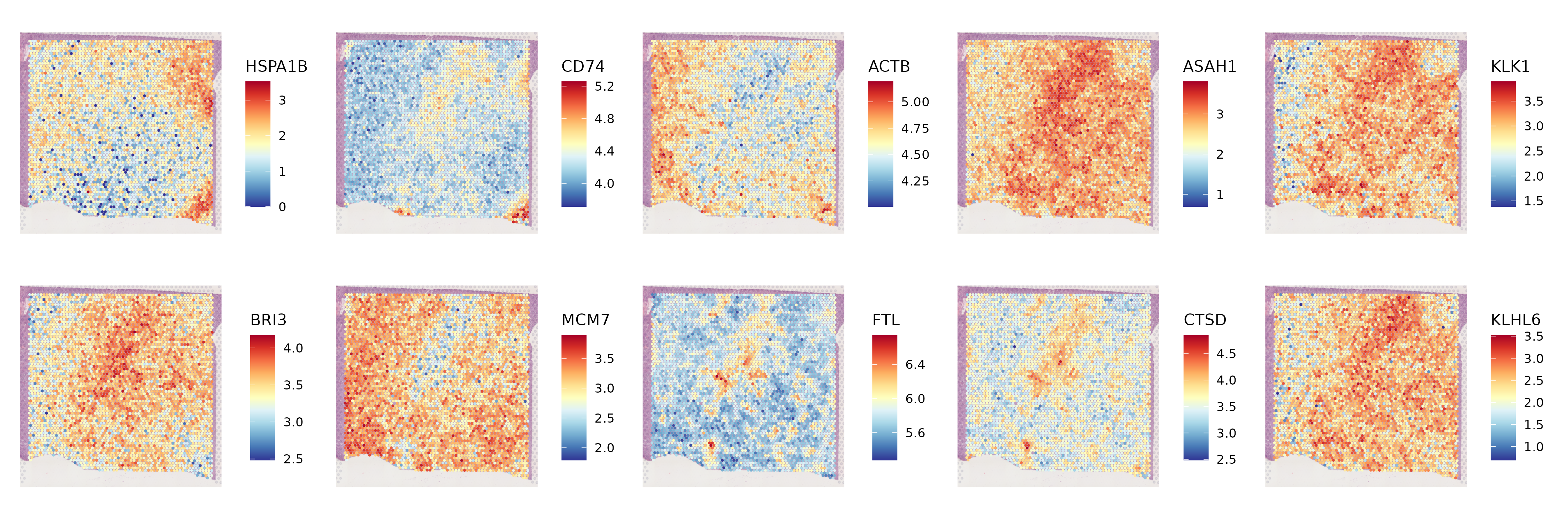
6.5 Step 5. Spatially variable features
The st_SpatiallyVariableFeatures function identifies and visualizes spatially variable features (SVFs) in spatial transcriptomics data. It integrates the identification of spatially variable features using a specified method, saves the results to a directory, and creates visualizations of the top spatially variable features.
6.5.1 Function arguments:
st_obj: The input spatial transcriptomics object containing the data for analysis.output.dir: The directory where output files will be saved. Default is the current directory.assay: The assay to be used for finding spatially variable features. Default is'SCT'.selection.method: The method used for selecting spatially variable features. Default is'moransi'.n.top.show: The number of top spatially variable features to visualize. Default is10.n.col: The number of columns for the visualization grid. Default is5.verbose: A logical flag to print progress messages. Default isFALSE.
6.5.2 Function behavior:
- Identify Spatially Variable Features: Identifies spatially variable features using the specified method and assay. Suppresses warnings during the process.
- Save Metadata: Extracts metadata features and saves them as a CSV file in
output.dir. - Visualization: Selects the top
n.top.showspatially variable features. Generates and saves a spatial feature plot of these features in the specified directory. - Return Value: Returns the updated
st_objcontaining the identified spatially variable features.
6.6 Step 6. Spatial interaction
The st_Interaction function is used to identify and visualize interactions between clusters based on spatial transcriptomics data. It utilizes Commot to analyze spatial interactions, identify pathway activities, and assess the strength and significance of interactions.
6.6.1 Function arguments:
st_data_path: Path to the spatial transcriptomics data.metadata_path: Path to the metadata associated with the spatial transcriptomics data.library_id: Identifier for the spatial transcriptomics library. Default is'Hema_ST'.label_key: Key in the metadata to identify cell clusters. Default is'seurat_clusters'.save_path: The directory where output files will be saved. Default is the current directory.species: The species of the spatial transcriptomics data. Default is'human'.signaling_type: Type of signaling interactions to consider. Default is'Secreted Signaling'.database: Database to be used for the analysis. Default is'CellChat'.min_cell_pct: Minimum percentage of cells to consider for interaction analysis. Default is0.05.dis_thr: Distance threshold for defining interactions. Default is500.n_permutations: Number of permutations for assessing significance. Default is100.pythonPath: The path to the Python environment containingCommotto use for the analysis. Default is ‘.’.
6.6.2 Function behavior:
CommotAnalysis: UsesCommotto perform interaction analysis, identifying interactions within and between clusters.- Visualization: Generates visualizations of pathway interactions and interactions between ligand-receptors (LRs) within and between clusters, and saves them in
save_path.
6.6.3 An example:
st_Interaction(
st_data_path = 'path/to/data',
metadata_path = 'path/to/metadata',
library_id = 'Hema_ST',
label_key = 'seurat_clusters',
save_path = '.',
species = 'human',
signaling_type = 'Secreted Signaling',
database = 'CellChat',
min_cell_pct = 0.05,
dis_thr = 500,
n_permutations = 100,
pythonPath = 'path/to/python'
)
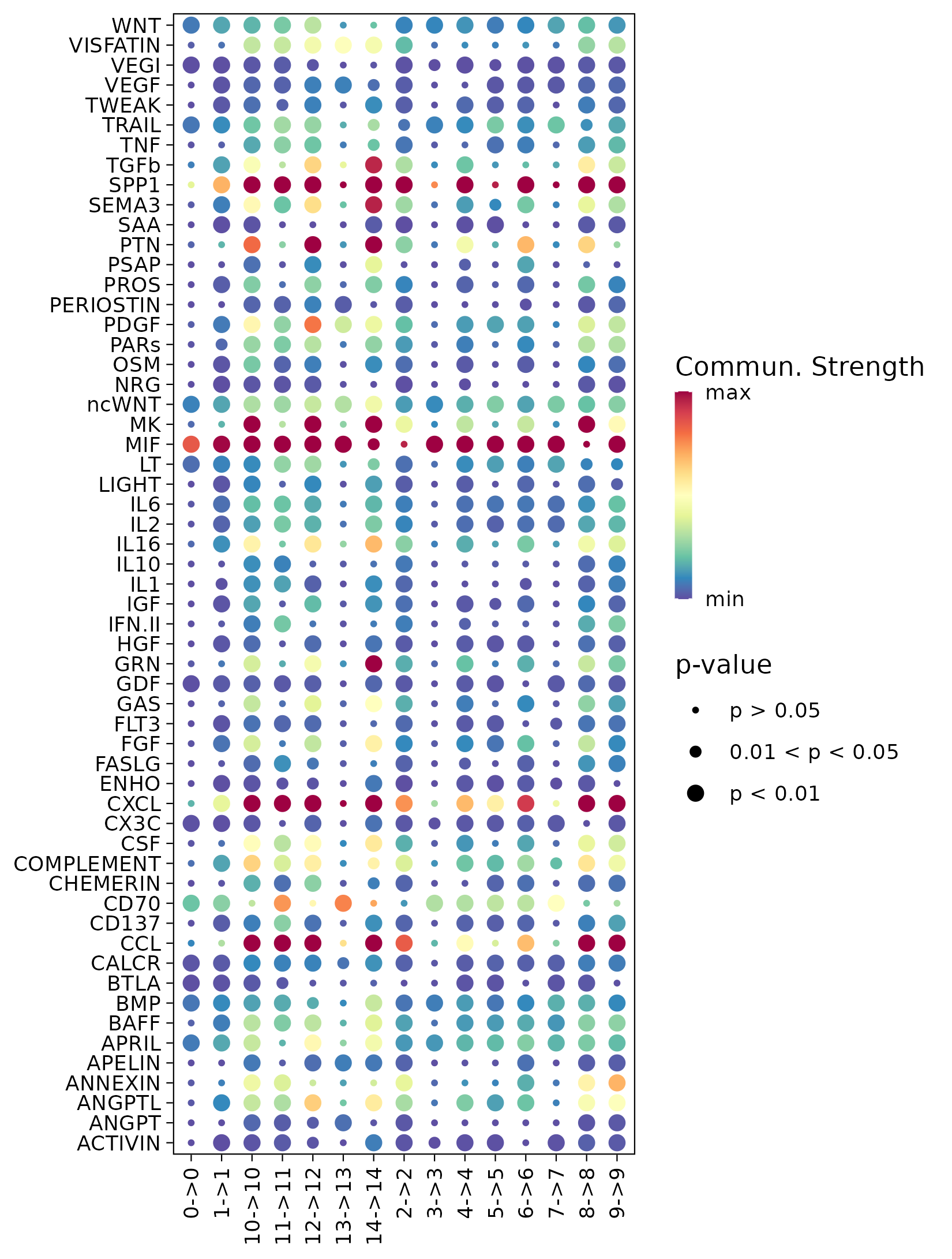

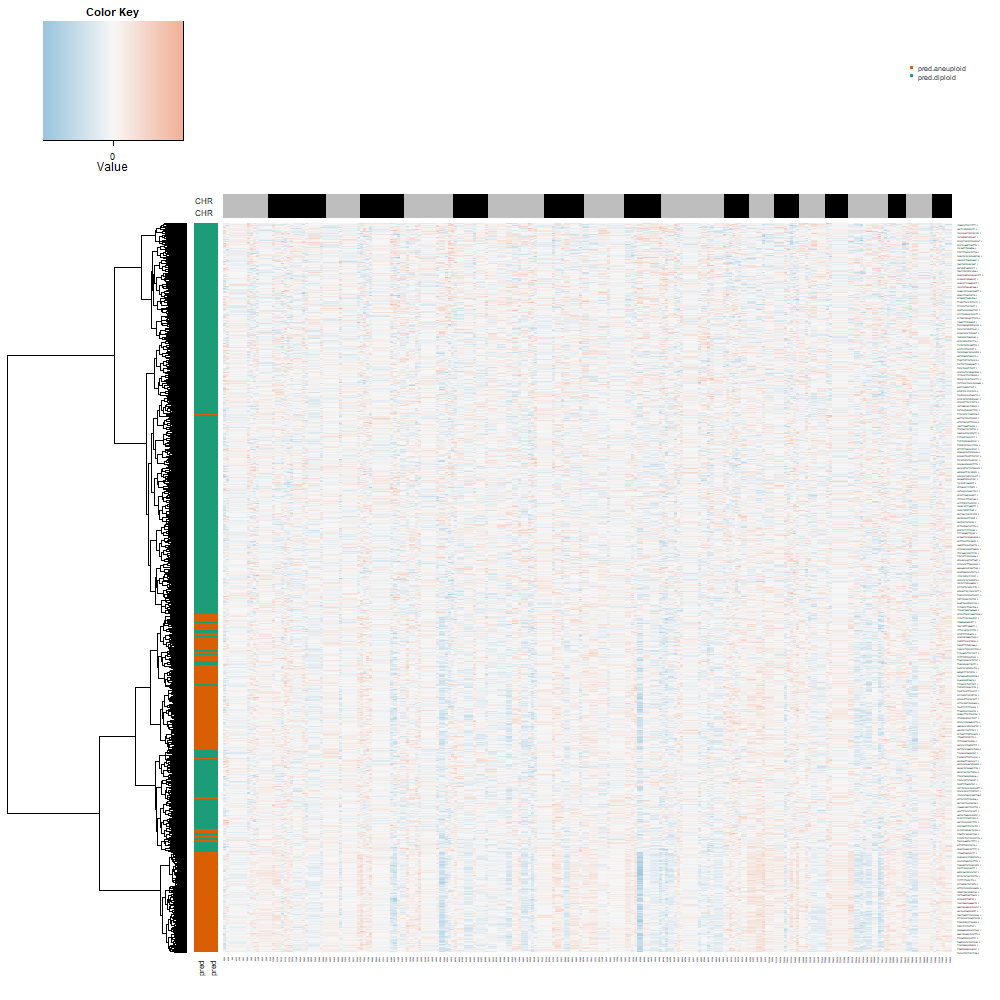
6.7 Step 7. CNV analysis
The st_CNV function identifies and visualizes copy number variations (CNVs) in spatial transcriptomics data. It uses CopyKAT to perform the CNV analysis, saves the results, and generates visual representations of CNV states.
6.7.1 Function arguments:
st_obj: The input spatial transcriptomics object containing the data for analysis.save_path: The directory where output files will be saved.assay: The assay to be used for CNV analysis. Default is'Spatial'.LOW.DR: The lower threshold for the dropout rate in CopyKAT. Default is0.05.UP.DR: The upper threshold for the dropout rate in CopyKAT. Default is0.1.win.size: The window size for the CNV analysis. Default is25.distance: The distance metric to be used for the analysis. Default is"euclidean".genome: The genome version to be used, ‘hg20’ or ‘mm10’. Default is"hg20".n.cores: The number of cores to be used for parallel processing. Default is1.species: The species of the spatial transcriptomics data. Default is'human'.
6.7.2 Function behavior:
- CopyKAT Analysis: Runs
CopyKATpipeline to perform CNV analysis using the provided parameters. - Saving Results: Saves the CopyKAT results as an RDS file.
- Plotting: Generates plots of the CNV states and saves them in
save_path. - Updating Metadata: Updates the spatial transcriptomics object with CNV state metadata.
- Return Value: Returns the updated
st_objcontaining the CNV state information.

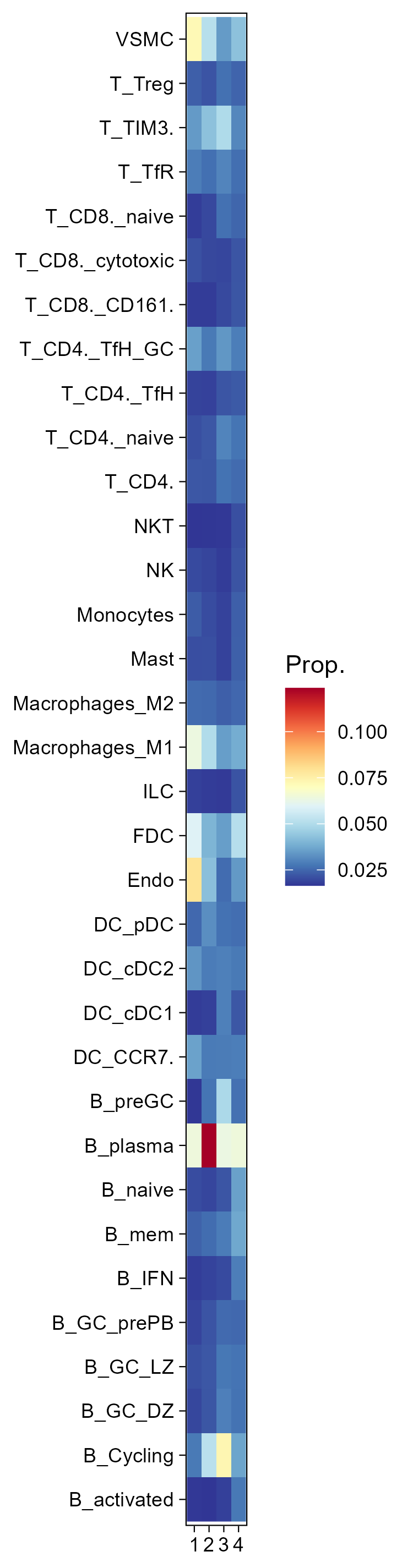
6.8 Step 8. Deconvolution
The st_Deconvolution function aims to perform spatial deconvolution analysis on spatial transcriptomics data to estimate the cell-type composition and abundance in different regions. The function utilizes cell2location to infer cell-type abundance and spatial distributions, allowing for the visualization and interpretation of spatially resolved cell populations within the tissue.
6.8.1 Function arguments:
st.data.dir: Path to the spatial transcriptomics data.sc.h5ad.dir: Path to the single-cell RNA-seq data in h5ad format. Default isNULL.library_id: Identifier for the spatial transcriptomics library. Default is'Hema_ST'.st_obj: Spatial transcriptomics object containing the data for analysis. Default isNULL.save_path: The directory where output files will be saved. Default isNULL.sc.labels.key: Key in the single-cell metadata to identify cell clusters. Default is'seurat_clusters'.species: The species of the spatial transcriptomics data. Default is'mouse'.sc.max.epoch: Maximum number of epochs used for single-cell deconvolution. Default is1000.st.max.epoch: Maximum number of epochs used for spatial deconvolution. Default is10000.use.gpu: Logical value indicating whether to use GPU for computation. Default isFALSE.use.Dataset: The dataset to be used for analysis, such as'HematoMap'or'LymphNode'.pythonPath: The path to the Python environment containingcell2locationto use for the analysis. Default is ‘.’.
6.8.2 Function behavior:
- Deconvolution Analysis: Performs the spatial deconvolution analysis using the provided spatial transcriptomics and single-cell RNA-seq data.
- Post-Analysis Processing: Processes the deconvolution results and visualizes the spatial distribution of inferred cell types within the tissue.
- Returning Results: If a Seurat object is provided, the updated Seurat object with cell type information is returned.
6.8.3 An example:
st_obj <- st_Deconvolution(
st.data.dir = 'path/to/data',
library_id = 'Hema_ST',
sc.h5ad.dir = NULL,
st_obj = st_obj,
save_path = '.',
sc.labels.key = 'seurat_clusters',
species = 'human',
sc.max.epoch = 1000,
st.max.epoch = 10000,
use.gpu = FALSE,
use.Dataset = 'LymphNode',
pythonPath = 'path/to/python'
)
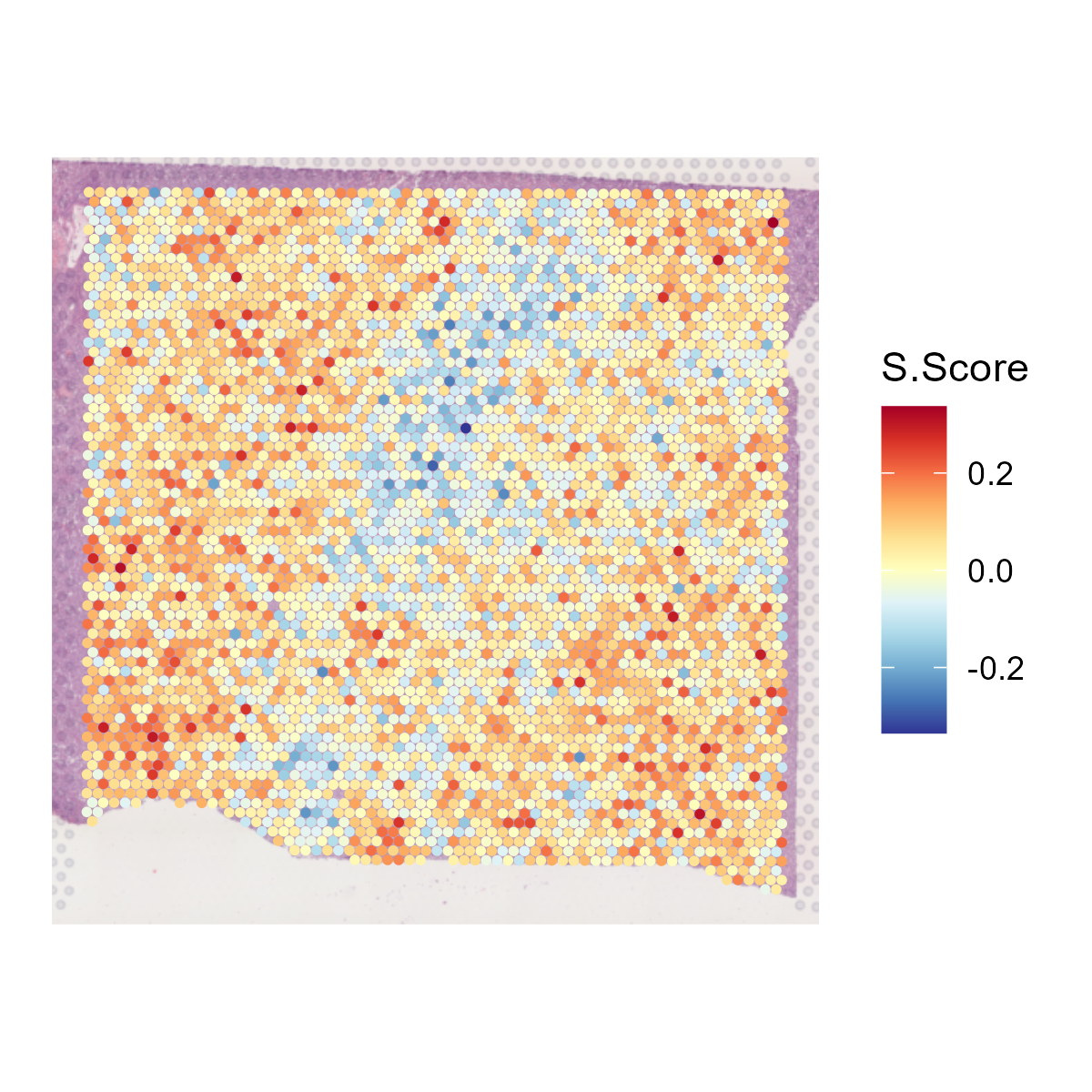
6.9 Step 9. Cell cycle
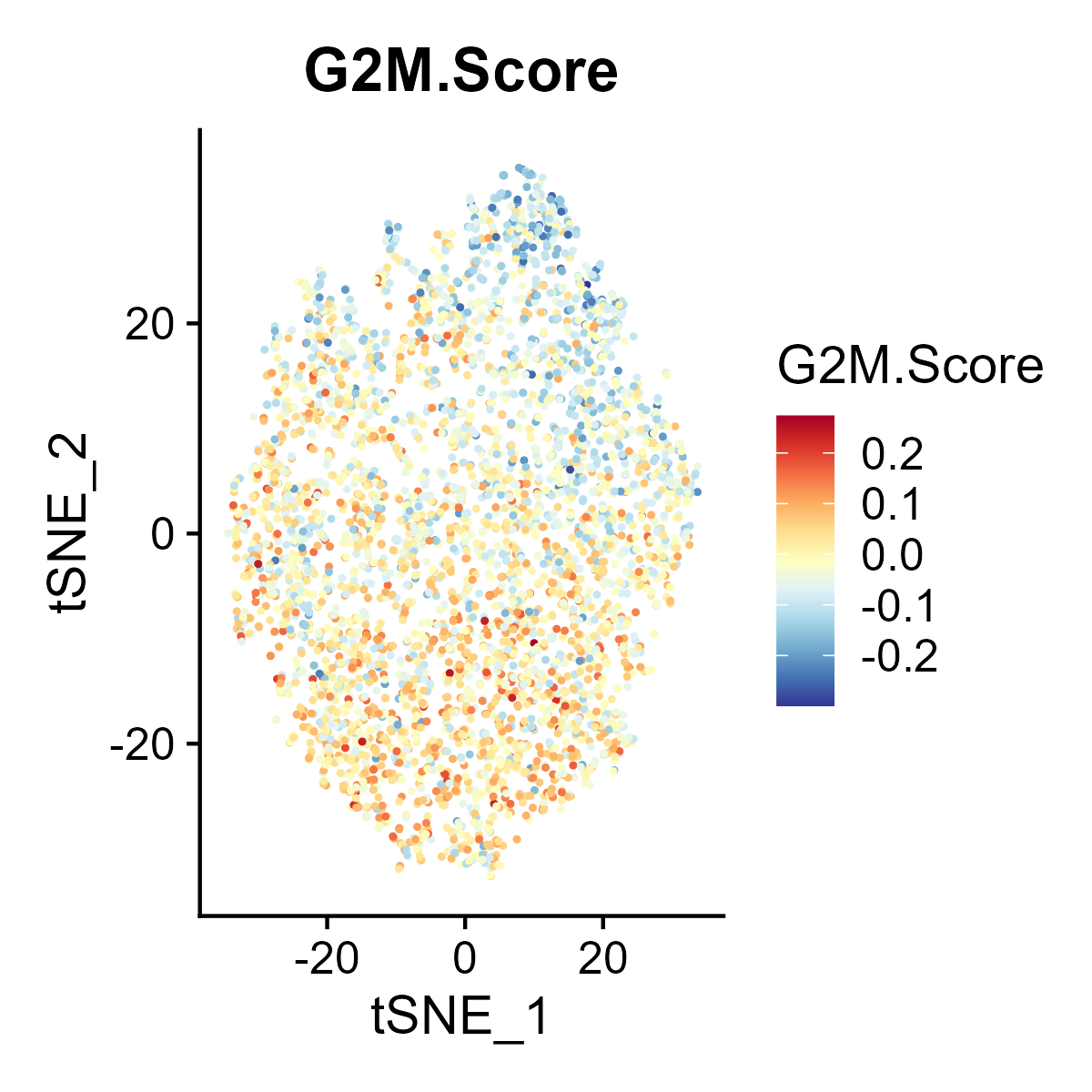
The st_Cell_cycle function is used to assess the cell cycle phase scores in spatial transcriptomics data. It calculates S phase and G2M phase scores based on the expression of designated cell cycle-related genes and visualizes these scores in spatial and dimensionality-reduced plots.
6.9.1 Function arguments:
st_obj: The input Seurat object containing the data for analysis.save_path: The directory where the output images will be saved. Default is the current directory.s.features: A list of genes associated with the S phase. Default is NULL (using genes from Seurat).g2m.features: A list of genes associated with the G2M phase. Default is NULL (using genes from Seurat).species: The species of the spatial transcriptomics data. Default is'human'.FeatureColors.bi: A color palette for visualization. Default is a two-color ramp palette.
6.9.2 Function behavior:
- Gene Feature Assignment: Assigns S phase and G2M phase gene lists based on the specified species or provided input.
- Cell Cycle Scoring: Calculates the S phase and G2M phase scores in the data.
- Spatial Visualization: Generates spatial feature plots to visualize the S phase and G2M phase scores using the specified color palette and saves the plots as images.
- Dimensionality-Reduced Plot Visualization: If UMAP or tSNE dimensionality reduction is available in the
st_obj, feature plots of the S phase and G2M phase scores are generated in the reduced space and saved as images. - Return Value: Returns the updated
st_objcontaining the cell cycle phase scores.
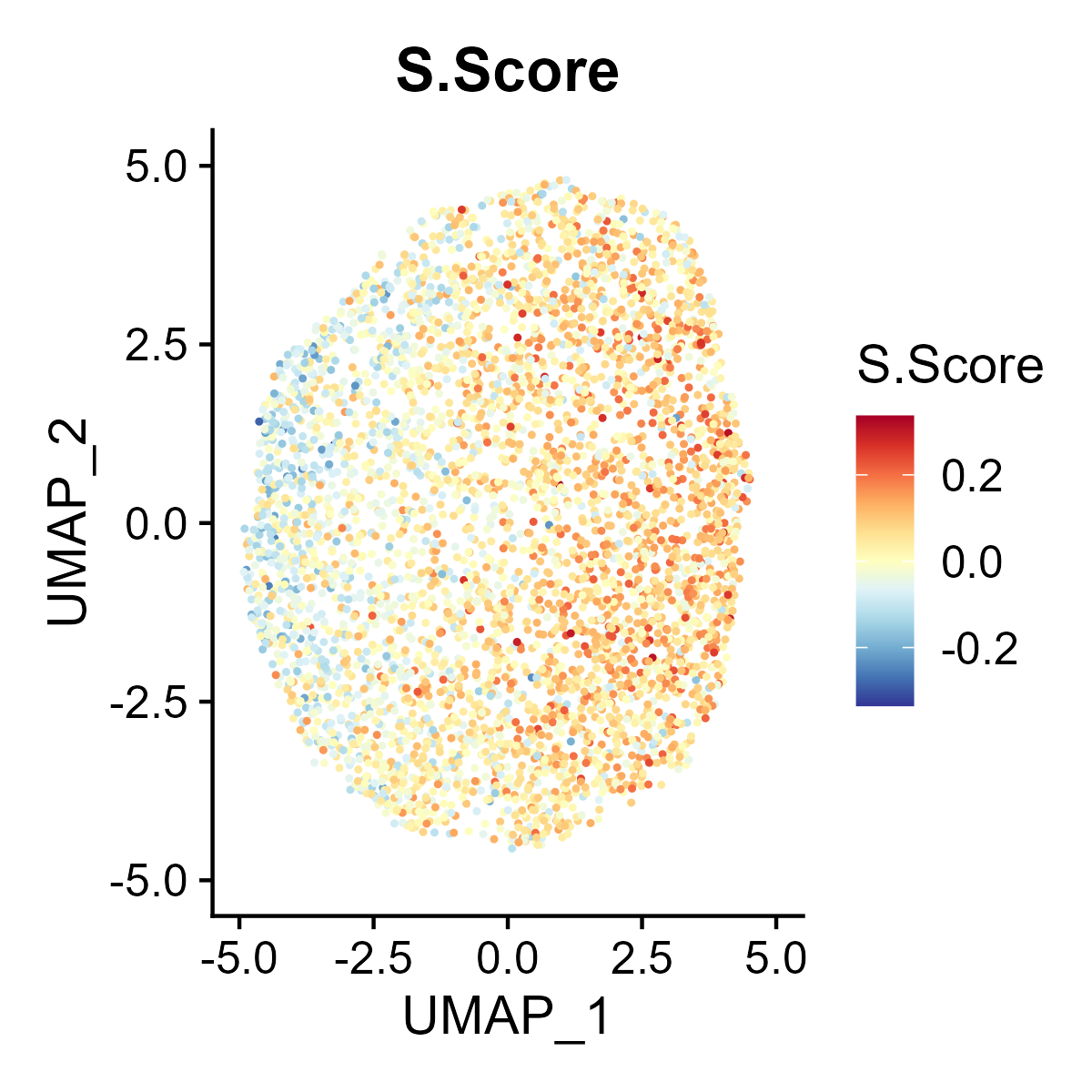
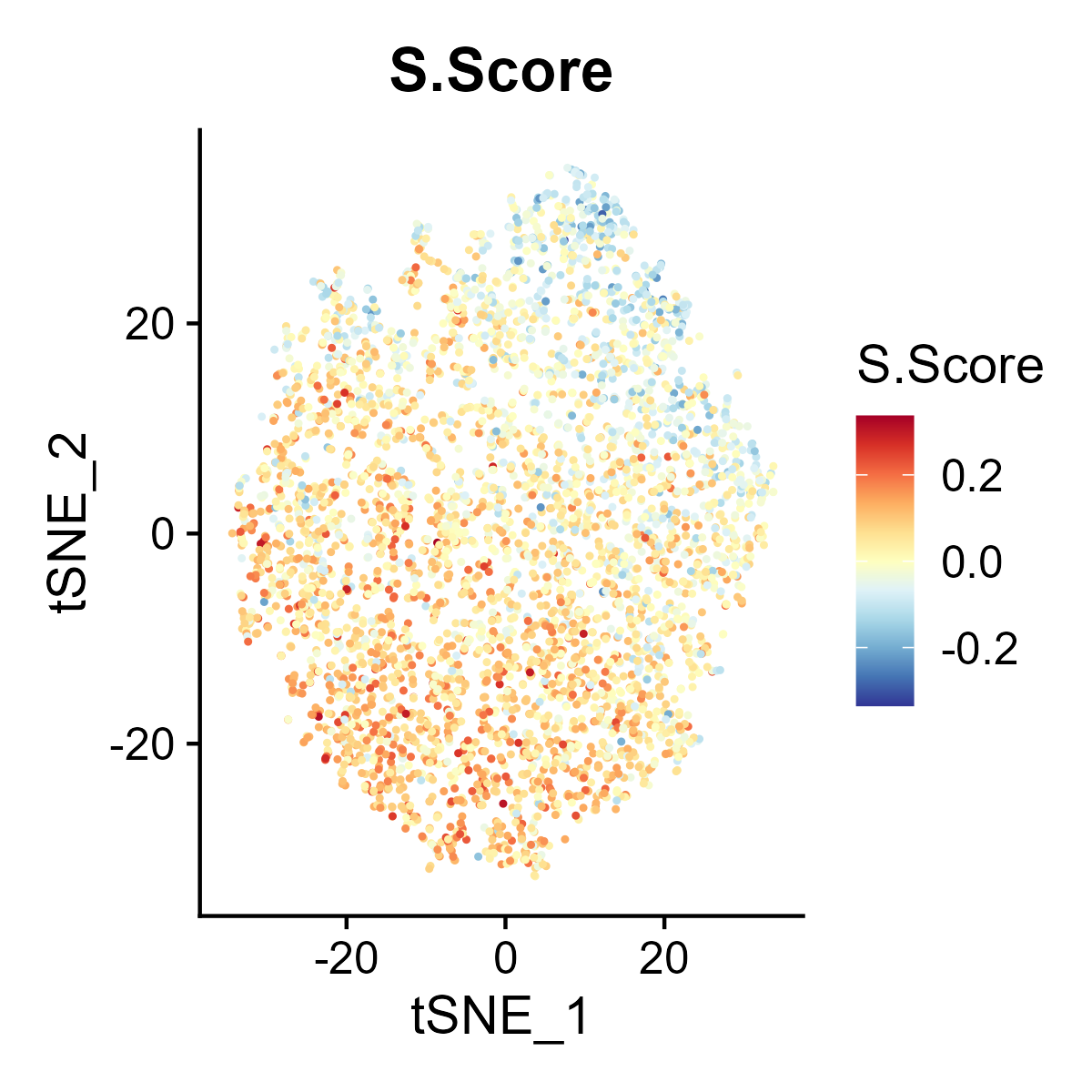
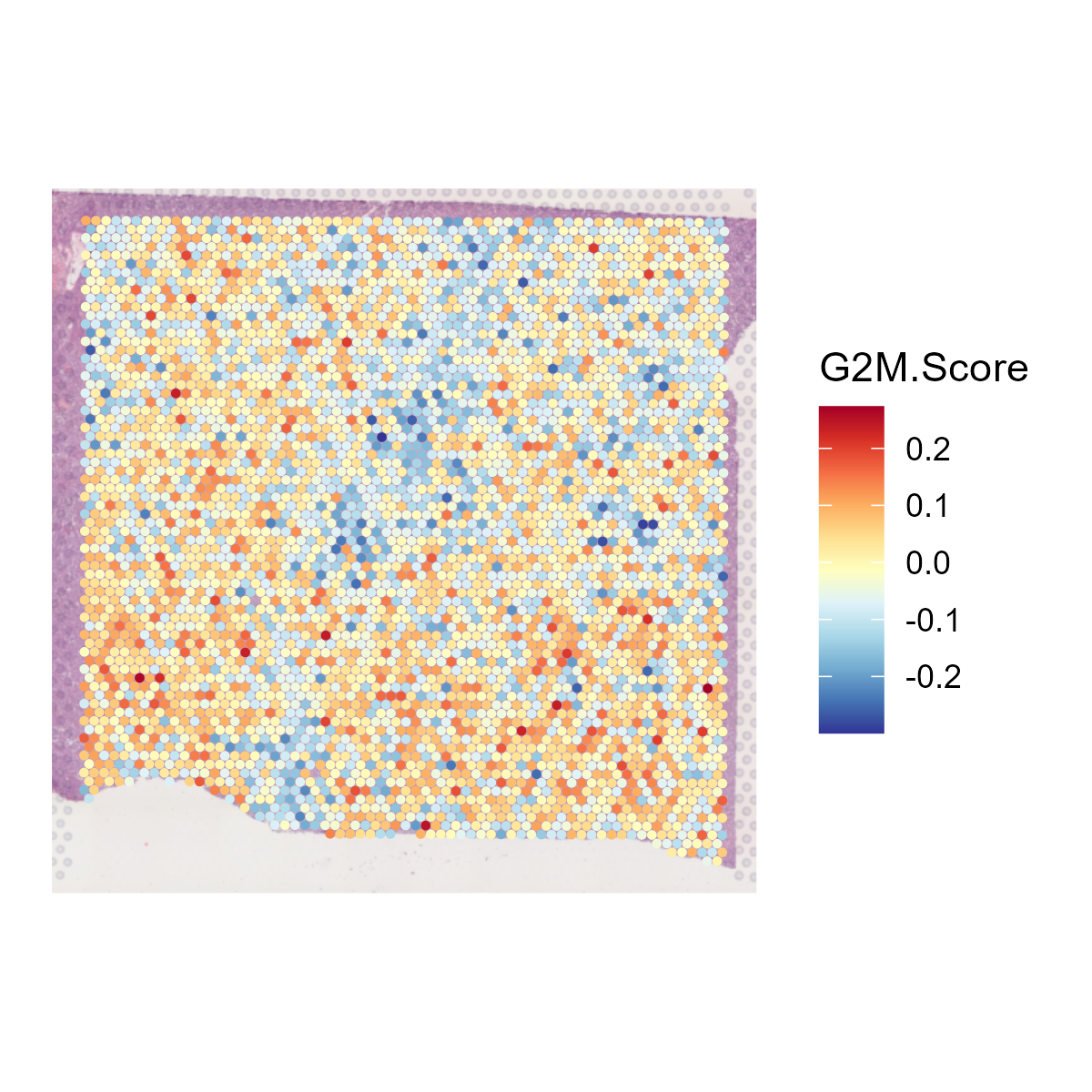
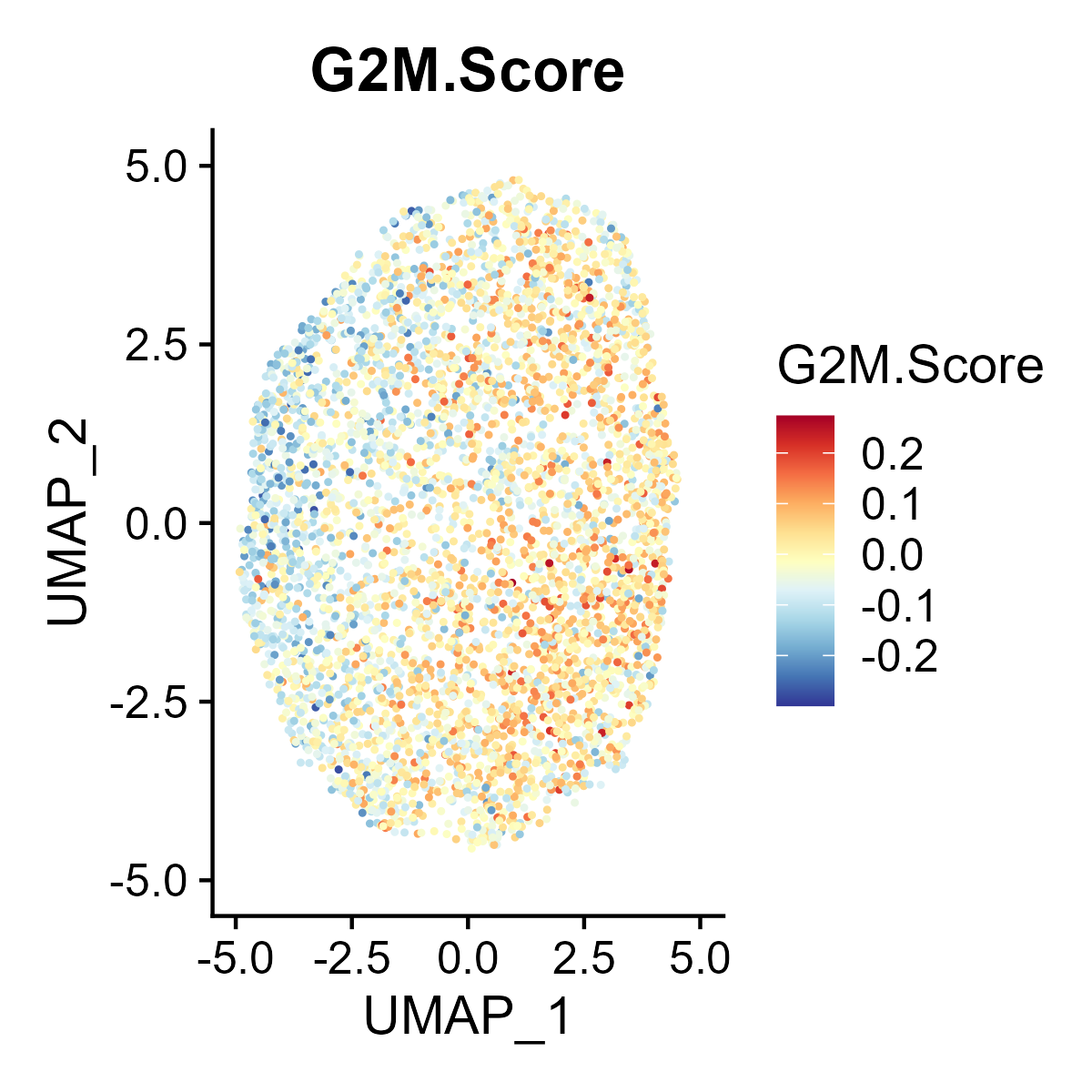
6.10 Step 10. Niche analysis
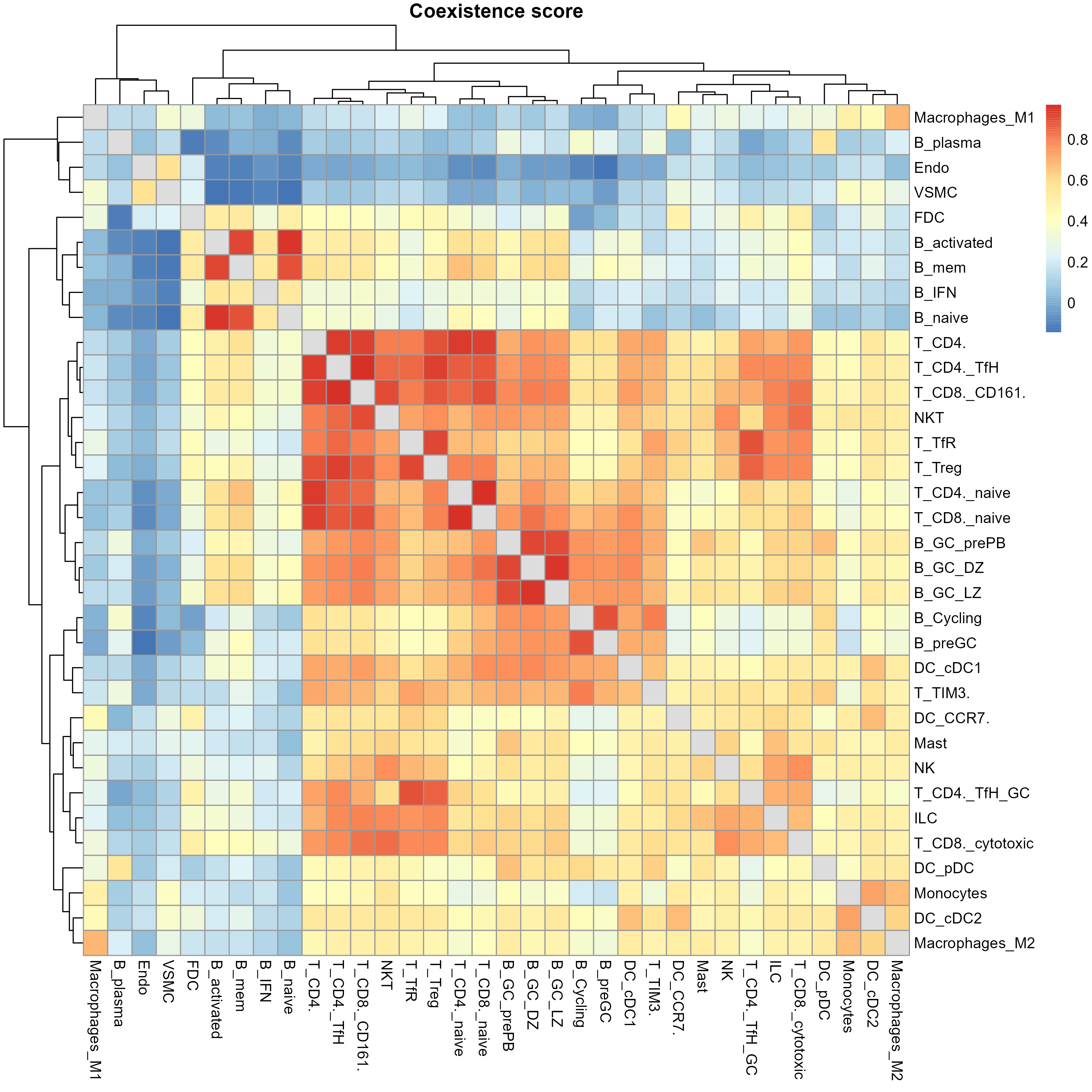
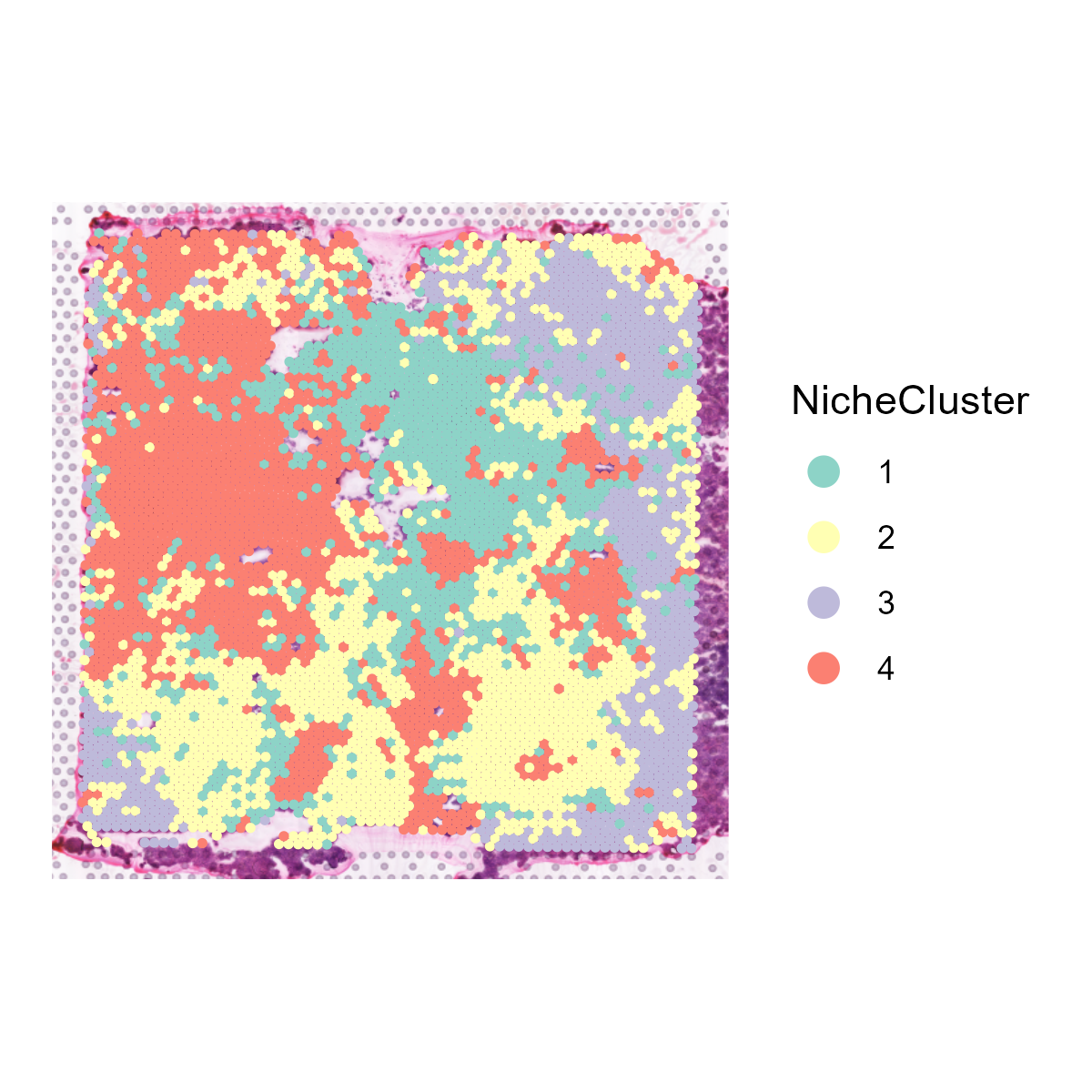
The st_NicheAnalysis function is designed to perform niche analysis on spatial transcriptomics data, enabling the exploration of spatial niches or microenvironments within the tissue. The function encompasses co-occurrence analysis, niche clustering, and niche interaction analysis to uncover the spatial relationships and characteristics of different cell populations or features.
6.10.1 Function arguments:
st_obj: The input SeuratObject containing the spatial transcriptomics data for analysis.features: A vector of features representing features (for example, cell types from deconvolution) for niche analysis.save_path: The directory where the analysis results and visualizations will be saved. Default is the current directory.coexistence.method: The method for co-occurrence analysis, accepting'correlation'or'Wasserstein'. Default is'correlation'.kmeans.n: The number of clusters for niche clustering. Default is4.st_data_path: A path containing the ‘spatial’ file and ‘filtered_feature_bc_matrix.h5’ file, required for niche interaction visualization.slice: The slice to be used for analysis. Default is'slice1'.species: The species of the sample data. Default is'mouse'.pythonPath: The path to the Python environment containingCommotto use for the analysis. Default is ‘.’.
6.10.2 Function behavior:
- Co-occurrence Score Calculation: Calculates the co-occurrence scores between the specified features using the chosen coexistence method (‘correlation’ or ‘Wasserstein’).
- Niche Clustering: Utilizes k-means clustering to identify distinct spatial niches based on the expression profiles of the selected features and visualizes the clustering results.
- Niche Interaction Visualization: If the
st_data_pathis provided, performs niche interaction visualization usingCommot, which is based on the provided spatial transcriptomics data and generates visualizations of niche interactions within the tissue. - Return Value: Returns the updated
st_objwith niche analysis results and visualizations.
6.10.3 An example:
tmp <- read.csv('path/to/cell2loc_res.csv',
row.names = 1)
features <- colnames(tmp)
if(!all(features %in% names(st_obj@meta.data))){
common.barcodes <- intersect(colnames(st_obj), rownames(tmp))
tmp <- tmp[common.barcodes, ]
st_obj <- st_obj[, common.barcodes]
st_obj <- AddMetaData(st_obj,
metadata = tmp)
}
st_obj <- st_NicheAnalysis(
st_obj,
features = features,
save_path = '.',
coexistence.method = 'correlation',
kmeans.n = 4,
st_data_path = 'path/to/data',
slice = `slice1`,
species = 'human',
pythonPath = 'path/to/python'
)